The ULTIMATE spam Filter (Nearest Neighbor IP address based mail Filter) Version 0.10 (Nearest Neighbor IP address based mail Filter) Version 0.10 |
| ★このドキュメントは,Linux上級者向けに書かれています.分かり難いかもしれません.ごめんなさい. |
[What's New]
- 2007・11・01にご連絡のあった重大なセキュリティホールを一つ潰しました.これまでのバージョンをお使いの方は,すぐに使用を中止し,必ず0.10以上にした上でお使いください.
- また,unicode-1-1-utf-7のメイルを閲覧する際に,内容が見えないという問題も修正しました.
- Makefile中の MAILDIR を変更するとインストールできないという問題も修正しました.
-D RESTRICTEDで作られる制限付きモードのNNIPFの最新版の動作状況を見ることができるサイトをオープンしています.メイルの操作や設定変更などはできませんが,NNIPFの動作はどういうものかは確認できます.
NNIPFの機能を整理しておくと,以下のようになります.
- 基本機能
- BIP,GIPのデータを参照してfilter.plによるメイルの自動仕分け.これは.forward, もしくは.qmailに書くことで簡単に設定可能.尚,filter.plはconf.plに書いてある$T1以上の弁別度を持つメイルは$TRASHに仕分けされると同時にIPアドレスをBIPに登録します.$T2以下の弁別度を持つ場合,$NEWに仕分けると同時にIPアドレスをGIPに登録します.このような特性があるため,信頼できるBIP,GIPを持っている場合,SPAM送信元のアドレスが変化しても,特別なトレーニングなしに,ある程度自動追従します.$T1>
弁別度 >$T2となる場合には,filter.plは~/Maildir/tmp/以下にメッセージを貯めます.これら$T1,$T2の値は,CONF/conf.plを書き換えるだけで変更できます.
- MTAOBに関して
- NNIPFはMTAOBを手がかりに相手のIPアドレスを割り出しますが,Received行のby以降にマッチするMTAOBが複数個表れる場合には,IPアドレスから計算した弁別度が最大になるものを採用します.これによってbyの部分を偽造したスパムもブロックできるようになります.
- BIP/GIPに関して
- BIP/GIPのファイルは,個人で持ってもいいし,複数人で共通のマスターBIP/GIPを持って,ユーザは小さなサイズのBIP/GIPを持つというディスクスペースの消費に配慮した運用を行うこともできます.CONF/conf.plに$MGOODIP,
$MBADIPという変数が定義されていますが,これがマスターの定義です.これに相当するファイルが存在しない場合は,$GOODIPと$BADIPのみを参照して動作します.
- WEBインタフェース
- WEBインターフェイスを起動した際の「SPAM CONSOLE」ページで以下の操作が行なえます.
- ~/Maildir/tmp: このディレクトリ内のメイルに関しては,A1)スパムかA2)ノーマルかの仕分けが行なえます.この仕分けと連動してIPアドレスがそれぞれ個人のBIPかGIPに登録されます.
- ~/Maildir/cur: このディレクトリ内では,GIPに登録されていない馴染みでないメイルが表示されます.ここで,A1)GIPへの登録,A2)スパムメールがまぎれていた場合それをスパムと分類することができます.A1の操作を行なうと,そのメイルは完全に正常になるので,以降表示されません.また,A2の操作によってBIPへの登録が起き,メイルを~/Maildir/trashに移動することができます.
- ~/Maildir/trash: この中にはスパムが溜まり続けています.これらに対して,A1)BIPへの登録をすることと,A2)スパムと誤分類されたメールをノーマルに仕分けする,2つの操作が行えます.trashの表示は,日付毎にまとめてあり,BIPに登録されても表示は消えません.
尚,SPAM CONSOLEページ上部には,マニュアルやIP ADDR MANAGEMENT, ADD ○○ in Boundaryページなどへのリンクもあります.
各メイルを表示する「SHOW MAIL」ページでは,ヘッダーの分析結果と,本文が表示されます.識別に用いられたIPアドレスは大きな文字で表示されますので,NNIPFがどの部分をIPアドレスとして取り出すのかを理解したい人はこのページを良く見ると分かる筈です.また,ヘッダーの分析結果には下記2種類のリンクが張られています.
- IPアドレスにはその弁別度を計算する「IP ADDR MANAGEMENT」ページへのリンクが張られており,クリックすることによりこのページにジャンプし,弁別度が計算できます.
- Boundaryファイルに格納されていないMTAをBoundaryファイルに格納する「Add ○○ in Boundary File」ページへのリンクが張られています.これをクリックすることで,MTAをBoundaryファイルに追加することが可能.
今後は,モジュール化,きたないchk.cgiの書き直し,デバッグなどを進めます.より長期的(1年以内)には,1)ディレクトリの階層構造を排除してファイルに格納されたIPアドレスの最近傍探索アルゴリズムを作る,2)我々が作っている受信メイル中で共起性の高い文字列辞書を生成するBayesianフィルタリングとドッキングすること,などを行なう予定です.
利用者の声:(使っていない人の意見は割愛してます)
- 1日10通くらい来ていたspamがきっちり止まりました。全然来ないと、おかしな話ですが物足りないですね。
- 携帯に転送しているメールからスパムが全くなくなったのが一番うれしい!ただドキュメントが不親切。
- こじまさんの感想(スパムの死んだ日)です.
- 素晴らしいメールフィルタを提供して頂きありがとう 御座います。 初期から試用しておりますがスパムメールが極端に減りTrashに引っ掛かってるスパムを見るとニヤニヤしてしまう今日この頃です。我が家の環境は今迄、Postfix+Procmail+Spamassassin
という環境でスパム駆除を行っておりましたがフィルタ にメールの学習をさせても全てを駆除できる程の物では ありませんでした。 しかしNNIPFを導入したところ98%程効果があり今や重宝
しております。
急ぐ人はここからダウンロードとインストールへ.
過去のバージョン全てセキュリティホールあり. 0.01-beta 0.02-beta 0.03-beta 0.04-beta 0.05-beta 0.06-release 0.08 0.09
| NNIPF とは ? |
NNIPF は sendmail, postfix, qmail などのメイル配送エージェント(MTA)上でユーザ定義のフィルタとして動作するスパムメイルフィルタです.
- 最近良く用いられるSMTP強制切断を行いRFC2821準拠でないものを落とす,あるいは,MTAの反応をわざと遅らせるSMTPターピットでスパムを受けないという対処法があります.しかし,この方法でも,一旦他のMTAで中継されたメイルは通り抜けます.また,最近は専用MTAからまっとうに送られてくるスパムも増えつつあるため,上記のチェックをしても約半数程度のスパムしか除去できないというのが現状です.
- このため,各ユーザが設定可能なスパム検出フィルターは依然として必要ですが,メイルのボディーを見て識別するタイプのフィルターは誤検出/未検出のミスをします.ちなみに,高額で導入したBayesian型スパムフィルタによって,重要書類が紛失という事故もあちこちで起きています.これ以外にも,「お姉ちゃんと一緒に帰る.」という子供のショートメイルが「お姉」というスパム確率の高い辞書エントリにマッチして,スパムに分類されるといった問題は,コンテンツ分析型のフィルタリングでは根本的な解決は極めて困難です.さらに,学習がいつどのように行なわれるのかがよく分からず,識別器をうまくトレーニングできないという方も多いと聞きます.
NNIPFが作られた背景は,以上の通りであり,基本的には誤りの少ないメールフィルタの実現ということが目標です.
誤りの少ないフィルタを作成するためには,メイルがスパムであるか否かを特徴付ける明確な特徴を見つける必要があります.NNIPFでは,我々が長年蓄積した100万通以上の大量のスパムデータを詳細に解析した結果,最も有効であると思われる「送信者の情報」を特徴として利用しております.これは,偽造されている可能性のあるメイルのヘッダー情報から,正しい送信者の情報を得るという問題を解決しなければなりません.このために,
「自分が外部からメイルを受けるときに使っている信頼できるMTA(Mail Transfer Agent)を登録しておき,そのMTAが生成したReceived:行から送信元のIPアドレスを割り出す」
という機能を実現しました.これにより,メイルヘッダーの偽造に対しても頑健な送信元アドレスの割り出しが実現できます.このときに登録する信頼できるMTAをNNIPFではMTA
On the Border (MTAOB)と呼ぶことにします.
MTAOBは外部からのメイルを受け付けている信頼できるMTAであり,これによって受信されたメイルは決まった配送経路でBase MTAに送られます.MTAOBは,外部の野蛮な世界に面しているMTAであり,MTAOB上では送信元のIPアドレスを正確に把握できます.通常,メイルヘッダーに含まれる多数の"Received"フィールドにはIPアドレスが書かれていますが,それらは偽造されたものであるかもしれないし,また一部は見飽きたものばかりです.しかし,MTAOBの生成した"Received"行には,図1吹き出し内の赤字の部分に示したように送信者の正しいIPアドレスが含まれているので,これを利用してスパム検出を行うことができます.Version
0.05からMTAOBが表れる全てのReceived行で後述する弁別度を計算し,その最大値を用いて識別を行うように変更しました.これによってスパマーが
by の偽造を行なっても,その影響を全く受けなくなりました.
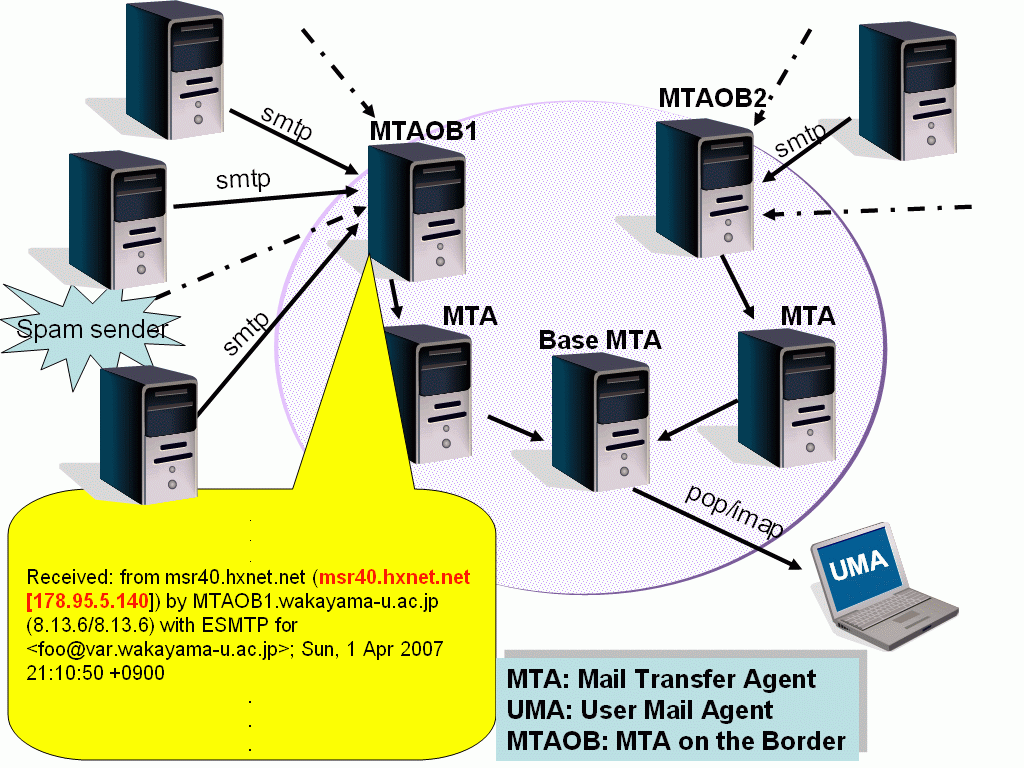 |
| 図1.MTAOBの概念図 |
次に問題となるのは,抽出されたIPアドレスが果たしてスパム送信者のアドレスか,そうではないのかを判断しなければなりません.IPアドレスのデータを記憶しておき,これに完全にマッチするものだけを分類する方法では,僅かに変化したIPアドレスに対処できませんので,何らかの識別が必要です.一般の識別問題では,従来Support
Vector Machine, ADABoostingなどの識別器が用いられてきました.また,メイルの識別問題ではメイル本文と,辞書内の単語やn-gramとのマッチングを行なうBayesianフィルタが良く用いられます.しかし,これらの手法は
- P1)学習に時間がかかる.
- P2)1回スパムや正常なメイルの学習データを与えただけでは再び同じ失敗をする可能性がある.
という欠点があるため,NNIPFでは最近傍識別器を用いています.(正確には,1-最近傍識別です.)
この手法は,「既知のスパム送信者のIPアドレス集合(BIP)」,および「既知の正常なメイル送信者のIPアドレス集合(GIP)」を事前に用意しておき,未知のメイルから抽出されたIPアドレスと,それぞれの集合との最短距離を計算し,より近い方に識別するという方式です.この方式の良さは,
- S1)学習にほとんど時間を要しない.
- S2)柔軟な識別面を構成でき,1つのデータを与えるだけで同じ間違いを繰り返さない.
という2点です.最近傍識別だけでは「スパムかNonスパムか」という二者択一的判断しか行なえませんが,NNIPFでは,最近傍識別理論に基づきながら,スパムらしさの指標となる「弁別度」という量を計算しております.
具体的には,
- Dspam:メイルのIPアドレスと,スパム送信者のIPアドレス集合の間の最短距離
- Dnormal:メイルのIPアドレスと,通常のメイル送信者のIPアドレス集合との最短距離
とすると,
が弁別度になります.これは,スパムと通常のメイルの生起確率密度分布をそれぞれ1/Dspam, 1/Dnormalとした場合の事後確率をBayes則で計算したのと同じ量です.お暇な人は計算してみてください.
この量が0であれば,確実に普通のメイルであり,1であれば確実にスパムメイルで,その中間の0.5であれば,どちらとも言えないということになります.システムでは,弁別度の値が0~0.35であれば正常,0.65~1であればスパム,そしてそれ以外は不確かというような扱いができるように作ってあります.(0.35や0.65の値はCONF/conf.pl
の$T2,$T1の値を変更することで調整できます.).現在登録しているスパム-IPアドレスは4千以上,Nonスパム-IPアドレスは千数百程度ですが,最近傍探索と弁別度の計算は一瞬で終わります.
これらを組み合わせて実現される「IPアドレスの最近傍識別」にどのような意味があるかという問題について考えてみます.もともと,IPアドレスは,国別,組織別,に割り振られており,勝手なIPアドレスを用いても通信は行なえません.したがって,スパム送信者のIPアドレスが大学や政府機関とは異なるアドレスに分布していることは容易に想像ができます.実際に,この分布を調べてみたところ,かなり明白な分布の偏りが存在することを確認しております.ですから,この方式では,怪しいMTAから送られてくるメイルを全てブロックできます.その一方で,まっとうな組織から送られてくるスパムメイルは検出できないという限界もあります.これは,ウイルスやワームに感染した正当な組織のコンピュータがスパム送信にABUSE(不正利用)されたケースに相当しますが,これは現在のところ前述したターピットや強制切断などの様々な対策の結果,ユーザまで送り届けられるケースは少なくなっております.実際,半年間運用してみた限り作者はこういうケースに遭遇しておりません.
NNIPFのプラットフォームは,ユーザの使っているMTAであり,ユーザはそこからPOPやIMAPなどのプロトコルを用いてメイルをダウンロードしています. ここで,スパム検出が行われるということは,ユーザは自分のPCにスパムメイルをダウンロードすることはないということです.これは,出張先などで低速の通信回線でインターネットに接続されている場合などで特に有利に働く特徴です.
NNIPFは現在のところ,我々が試した他のフィルタよりも精度およびスピードの点で優れていますが,人間の作ったソフトウエアは間違いを起こすものであり,NNIPFも例外ではありません.間違いを起こした場合,NNIPFはWEBインターフェイスを通じて誤りを修正し,フィルターを再トレーニングすることができます.これが行なえるためには,
- MTA, POP/IMAPサーバ,WEBサーバの3つが動いている計算機
がプラットフォームとして必要になります.NNIPFは,このようにどこでも動くというわけではないので,これは1つの欠点と見なせます.(以降,NNIPFが動いている計算機のことを以降
Base MTAと呼びます.)
NNIPFは,スパムメイルとして検出したメイルを全て蓄積しており,それらはWEBを介して見ることができます.もし,ユーザが誤分類を発見した場合には,それをWEB経由で修正することができるようになっています.これは,同時に識別器の再トレーニングにもなっており,この修正以降は同じ間違いは2度としません.
問題点など.
- 現在のバージョンでは,IPアドレスのデータをディレクトリの階層構造を利用して蓄積しています.ですので,i-nodeを大量に消費します(小飼さんからの指摘).それだけではなくext3のファイルシステムでは数百MBのディスク領域を消費してしまいます(こじまさんに教えてもらいました).複数人で使う場合にはマスターBIP/GIPと,各個人のBIP,GIPを分けて使う(TODO参照)ようにすれば,この問題はある程度緩和できます.また,B-treeベースで,i-nodeを動的に確保するXFS,JFS,ReiserFSなどのファイルシステムを利用すると,もう少し楽になります.これらのファイルシステムは,ディスクが空いている限りi-nodeの枯渇はなく,ext3に比べるとかなり少ないディスクスペースですみます.DBMなどのデータベースを用いた場合,データをメモリにロードしないで効率のよい最近傍探索が行えないという問題があるため,解決は容易ではありません.この問題については,研究として取り扱うため,1年後くらいに決着が付く予定です.
- botが正常なMTAを用いてスパムを送る場合,この方法では正常なMTAがスパム送信元として登録されるのではないかという懸念があります.これは,昔はそうでしたがISPの努力により,こういったケースは非常に減っています.かなり遠慮気味に書けば,NNIPFは様々な方法で減らされた残りのスパムを取り除くという現代的な問題に対するする処方箋とも言えます.むろん,NNIPFだけでも高精度でSPAMがはじけます.(本当にそういう状況が発生した場合に備えて,Bayesianフィルタの辞書自体をメイルの束から共起性に基づいて学習するフィルタを作っています.すでに動いていますが,AC法でマルチテンプレートマッチングを行なうので,そのためのオートマトンのロードに時間がかかる,共起性辞書の生成に時間がかかるなどの問題点に対する解決を行なってから,IPアドレスの入り混じった部分からのメイルをこれで判定させるという方法を採りたいと思います.)
- 作者は,本業が忙しいので,「使ってるよ」とか,暖かい言葉をかけてやらないと,そのうち放り投げる可能性が高いです.バグ情報,使用感等について,あるいはスパムでも構わないので,メールしてやるとバージョンアップのスピードが速くなります.
|
ダウンロードとインストール
[無保証]
尚,このソフトウエアの使用により被った被害については,作者は一切責任を取りませんので,使用者側で問題が生じないかどうかを十分テストをした上で運用して下さい.
[著作権]
各プログラムをご覧下さい.
2007年4月6日0.01beta公開,同日0.02beta,15日0.03beta,18日0.04betaに改訂,21日早朝0.05beta,
23日0.06release 25日0.07fix,26日0.07fixfix,0.07final,28日0.08,5月11日0.09,11月1日0.10
作者:
和歌山大学 システム工学部 和田俊和(twada@ieee.org)
謝辞: 本プログラムは,平成17年度(H17-H18)和歌山大学「オンリー・ワン創成プロジェクト経費」の補助を受けて開発されました.